psql + Zellij = ❤️
Étant souvent amené à utiliser Postgres comme gestionnaire de base de données, je n'ai jamais vraiment eu de préférence pour un client en particulier.
J'ai utilisé PgAdmin, DBeaver, Datagrid, divers plugins dans VSCode et j'ai toujours eu l'impression de disposer d'une usine à gaz pour vouloir exécuter la plupart du temps une simple requête SQL.
Bien sûr, il y a également le CLI psql, mais sans un minimum de configuration, son usage ne répond pas non plus à mes attentes.
Alors, cet après-midi, je me suis posé la question, "Quel est le MVP du client Postgres que j'utiliserais pour répondre à 95% de mes usages ?"
Mes besoins sont de pouvoir :
Me connecter rapidement à une base de données.
Écrire des requêtes facilement.
Gérer mes requêtes favorites.
Exploiter clairement mes résultats.
Sauvegarder mes résultats.
psql sans configuration ne répond pas à mes besoins. Mais, en se rapprochant de sa documentation, il ne semble pas si compliqué à paramétrer. Creusons un peu ⛏️.
Pour me connecter rapidement, je veux pouvoir sauvegarder les accès à mes bases de données. Dans cette documentation nous apprenons que le fichier .pg_service.conf répond à ce besoin et se présente de la manière suivante :
[my-local-db]
host=localhost
port=5432
dbname=mydb
user=myuser
Puis, à l'aide de la variable d'environnement PGSERVICE, nous pouvons cibler quelle configuration utiliser :
PGSERVICE=my-local-db psql
Vous remarquerez que je n'ai pas précisé le mot de passe de ma base de données dans ce fichier de configuration car je préfère garder mes mots de passe dans un gestionnaire de mots de passe.
->Me connecter rapidement à une base de données ✅
Continuons la lecture et découvrons le fichier .psqlrc permettant de vraiment customiser notre client :
\set QUIET 1 -- Désactive l'affichage des messages d'information.
\set PROMPT1 '%M:%> %n@%/%R%#%x ' -- Définit le prompt de la ligne de commande.
\set PROMPT2 '> '
\pset null '(null)' -- Définit comment les valeurs NULL sont affichées.
\set COMP_KEYWORD_CASE upper -- Force la casse des mots-clés SQL en majuscules lors de l'auto-complétion.
\timing -- Active le timing pour afficher combien de temps chaque requête prend.
\set HISTFILE ~/.psql_history_ :HOST _ :DBNAME -- Définit le fichier dans lequel l'historique des commandes est enregistré.
\set HISTCONTROL ignoredups -- Ignore les commandes en double dans l'historique.
\unset QUIET -- Réactive l'affichage des messages d'information.
On passe d’un prompt par défaut :
postgres=>
à un prompt plus explicite :
localhost:5432 myuser@mydb=>
Nous avons un historique des commandes dans lequel nous pouvons naviguer comme nous le ferions avec bash , en se servant par exemple de ctrl+r pour retrouver nos précédentes requêtes.
L’un des avantages de psql est l’usage des metacommandes. L’une d’elles m'intéresse particulièrement puisqu'elle permet d'éditer les requêtes avec l'éditeur de son choix.
Pour choisir son éditeur, il faut ajouter la variable d'environnement PSQL_EDITOR dans notre script .psqlrc :
\setenv PSQL_EDITOR "/usr/bin/vim"
puis d’exécuter \e .
->Écrire des requêtes facilement ✅
psql donne aussi la possibilité de créer des alias à l’aide de la metacommande \set.
Ici je sépare mes requêtes dans des fichiers sql pour ne pas surcharger mon fichier de configuration :
\set tablesizes `cat ~/aliases/table_sizes.sql`
Le contenu de aliases/table_sizes.sql :
WITH table_sizes AS (
SELECT
schemaname,
tablename,
pg_total_relation_size(format('%I.%I', schemaname, tablename)) AS table_size
FROM
pg_tables
WHERE
schemaname NOT IN ('pg_catalog', 'information_schema')
)
SELECT
schemaname,
tablename,
pg_size_pretty(table_size) AS table_size
FROM
table_sizes
ORDER BY
table_size DESC;
Je n'ai plus qu'à exécuter :tablesizes .
Entre l’historique de mes commandes et la création d'alias :
-> Gérer mes requêtes favorites ✅
Par défaut, psql utilise pour afficher les résultats d’une requête la commande Linux more . Ce qui produit pour des tables avec beaucoup de colonnes un affichage qui peut ressembler à cela :
Une première solution serait de remplacer more par less , afin d’obtenir un meilleur formatage. Mais en poussant un peu mes recherches je suis tombé sur pspg qui va améliorer cet affichage et apporter d’autres fonctionnalités comme celles de pouvoir utiliser sa souris ou encore gérer des exports.
Après avoir installé cet outil, il suffit de reprendre le fichier de configuration .psqlrc et d’y ajouter :
\setenv PSQL_PAGER "pspg"
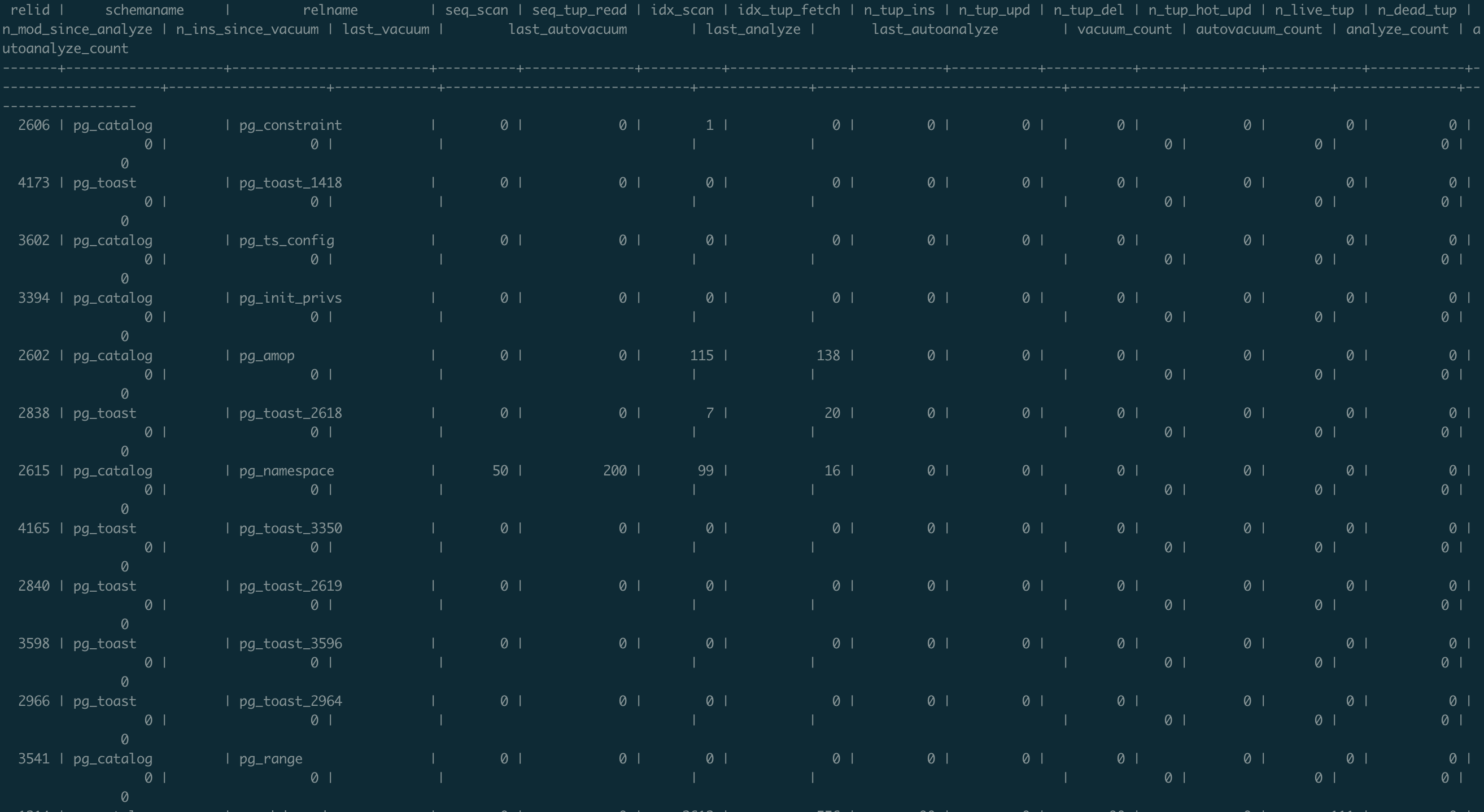
Nos résultats de requêtes ressemblent désormais à cela :
→ Exploiter clairement mes résultats ✅
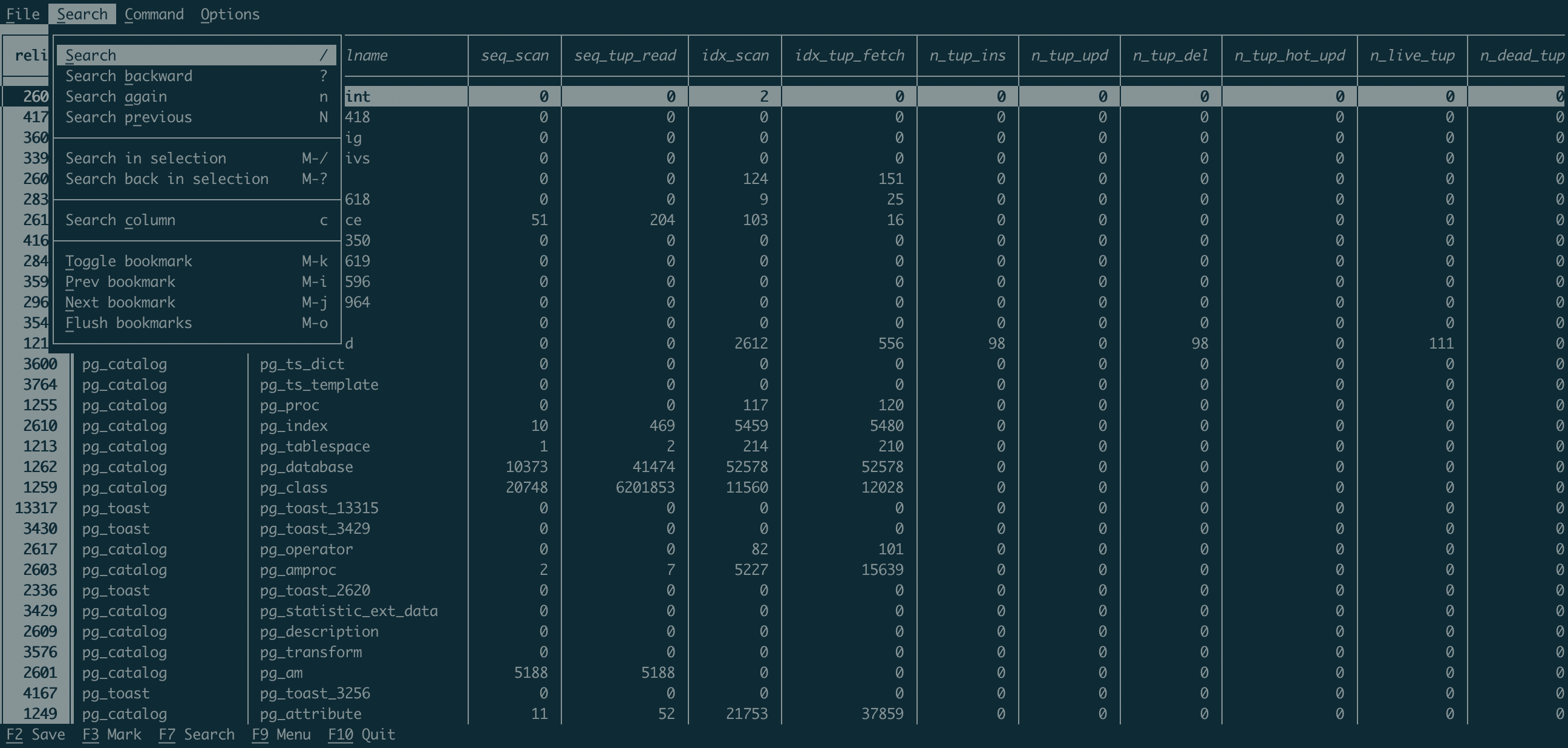
Parmi les menus accessibles depuis notre nouvelle vue de résultats, il y a celle de pouvoir copier et exporter facilement :
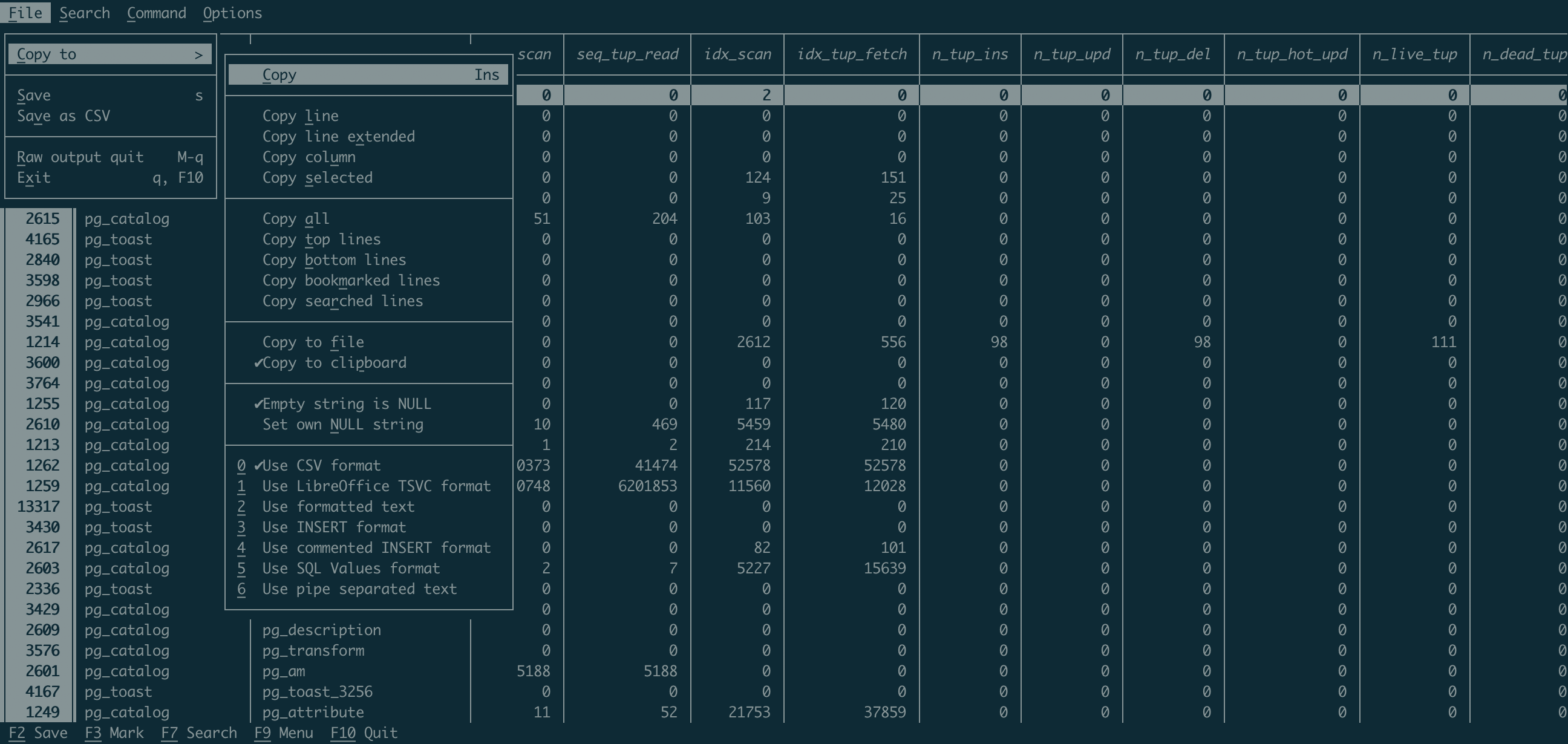
-> Sauvegarder mes résultats ✅
La réalisation de mon MVP est proche mais à l’usage je m’aperçois qu’il est assez embêtant de devoir toujours fermer mes résultats pour revenir au prompt de psql . C’est ici qu’intervient Zellij. Zellij c’est un terminal workspace, comparable à tmux, implémenté en Rust , que j’utilise depuis plusieurs mois.
Cerise sur gateau, psql permet de rediriger le stream de ses outputs vers un pipe. Miracle, pspg permet de lire le stream de ses inputs depuis un pipe.
Je configure mon layout Zellij :
layout {
default_tab_template {
pane size=1 {
borderless true
plugin location="zellij:compact-bar"
}
children
pane size=2 {
borderless true
plugin location="zellij:status-bar"
}
}
tab name="psql" {
pane name="data" {
command "~/.config/zellij/layouts/pspg.sh"
}
pane size="30%" focus=true borderless=true{
command "~/.config/zellij/layouts/psql.sh"
}
}
}
psql.sh :
#!/usr/bin/env bash
PGSERVICE=$PGSERVICE psql -o pipe
pspg.sh :
#!/usr/bin/env bash
sleep 1 # permet d'attendre le lancement de psql avant pspg.
pspg -f pipe --stream
Finalement assez rapidement, j’obtiens un client assez léger, rapide à lancer, qui répond à tous les besoins de mon MVP :
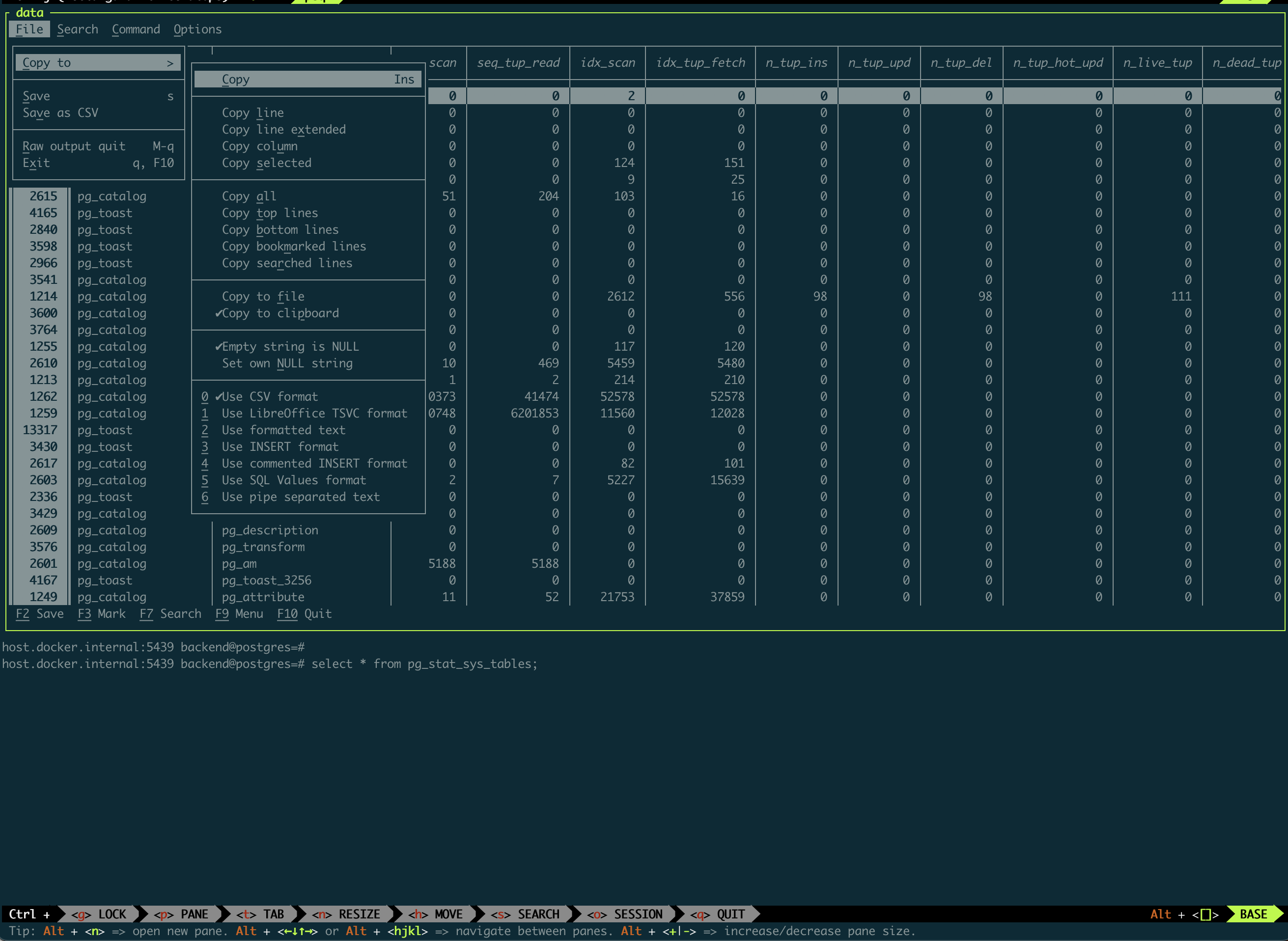
Mission complete !